L’anonymisation des corpus oraux : masques et costumes
30 janvier 2023
En rassemblant une grande quantité de corpus oraux, le Fonds de données linguistiques du Québec fait résonner de façon inédite les nuances historiques, géographiques et sociales du français québécois. Fondamentalement, cette entreprise n’est envisageable que grâce à la participation, à différentes époques, de centaines de locuteurs ayant généreusement confié leur voix aux auteurs de corpus. En contrepartie de cette générosité, il incombe à la communauté des chercheurs de protéger la vie privée des témoins. Cette responsabilité est d’autant plus grande dans le cas d’une diffusion publique.
Tous les éléments qui pourraient permettre de retracer les témoins sont ainsi retirés des entrevues. Ces éléments peuvent être explicites (prénom, nom, adresse, numéro de téléphone, date de naissance, etc.) ou plus implicites (nom de l’employeur, noms du conjoint ou d’amis, engagements publics possiblement médiatisés, profession peu fréquente, etc.). Sachant qu’une accumulation de détails en apparence banals peut mener à l’identification d’une personne, un contrôle serré des informations implicites est effectué. La rigueur est d’autant plus essentielle que l’Internet permet aux détectives en herbe de parfois dénicher certaines informations autrefois inaccessibles. À une autre époque, il aurait été laborieux de retracer le nom d’un chansonnier amateur ayant joué 10 ans auparavant dans un bar de quartier désormais fermé. Aujourd’hui, il n’est plus toujours impossible de retrouver l’information en ligne.
L’anonymisation des entrevues se fait à la fois dans les transcriptions et les fichiers sonores. Dans le texte, les éléments retirés sont remplacés par un substantif générique précédé d’un N, signalant le masquage (ex. « J’ai parlé à Nprénom de la job à Nentreprise »). Par rapport à une approche où les éléments retirés seraient absents ou remplacés par des X, cette façon de faire permet de maintenir l’intelligibilité des transcriptions. Dans l’audio, les éléments problématiques sont remplacés par un bruit ayant la même durée et la même courbe intonative, ce qui permet de conserver une partie du contenu linguistique des données originales.
Un des problèmes associés à cette approche est une certaine aseptisation des entrevues. Les noms de personnes, de lieux et d’organisation, entre autres, donnent une couleur particulière au témoignage de chaque locuteur, couleur qui est éliminée lors du processus d’anonymisation. Un autre problème, plus sérieux, est l’opacité qui découle de l’élimination d’une grande proportion des éléments nominatifs d’une entrevue. En effet, il est difficile d’interpréter adéquatement une phrase comme « Nprénom m’a dit que Nprénom était parti de Ninstitution parce que Nnom de Ninstitution l’a recruté ».
Une solution élégante à ces deux problèmes est le recours à des pseudonymes. Ceux-ci permettent de réinsuffler un peu de caractère dans les entrevues anonymisées et de bien distinguer les individus qui y sont mentionnés. La pseudonymisation n’est pas une stratégie nouvelle dans le monde de la linguistique québécoise; elle s’est imposée entre autres dans les travaux issus du corpus Sankoff-Cedergren (1971). Remplaçant les codes numériques employés à l’origine, des noms d’emprunt ont été créés pour référer aux témoins. Ainsi, les chercheurs familiers avec le corpus reconnaîtront spontanément Lysiane, Lucille et Alain, sans nécessairement connaître leur identifiant « officiel » (respectivement les entrevues 7, 84 et 104). Pour l’instant, l’usage de ces pseudonymes se limite aux publications, mais il serait aisé de les intégrer aux transcriptions elles-mêmes, où ils remplaceraient les attributions par code numérique.
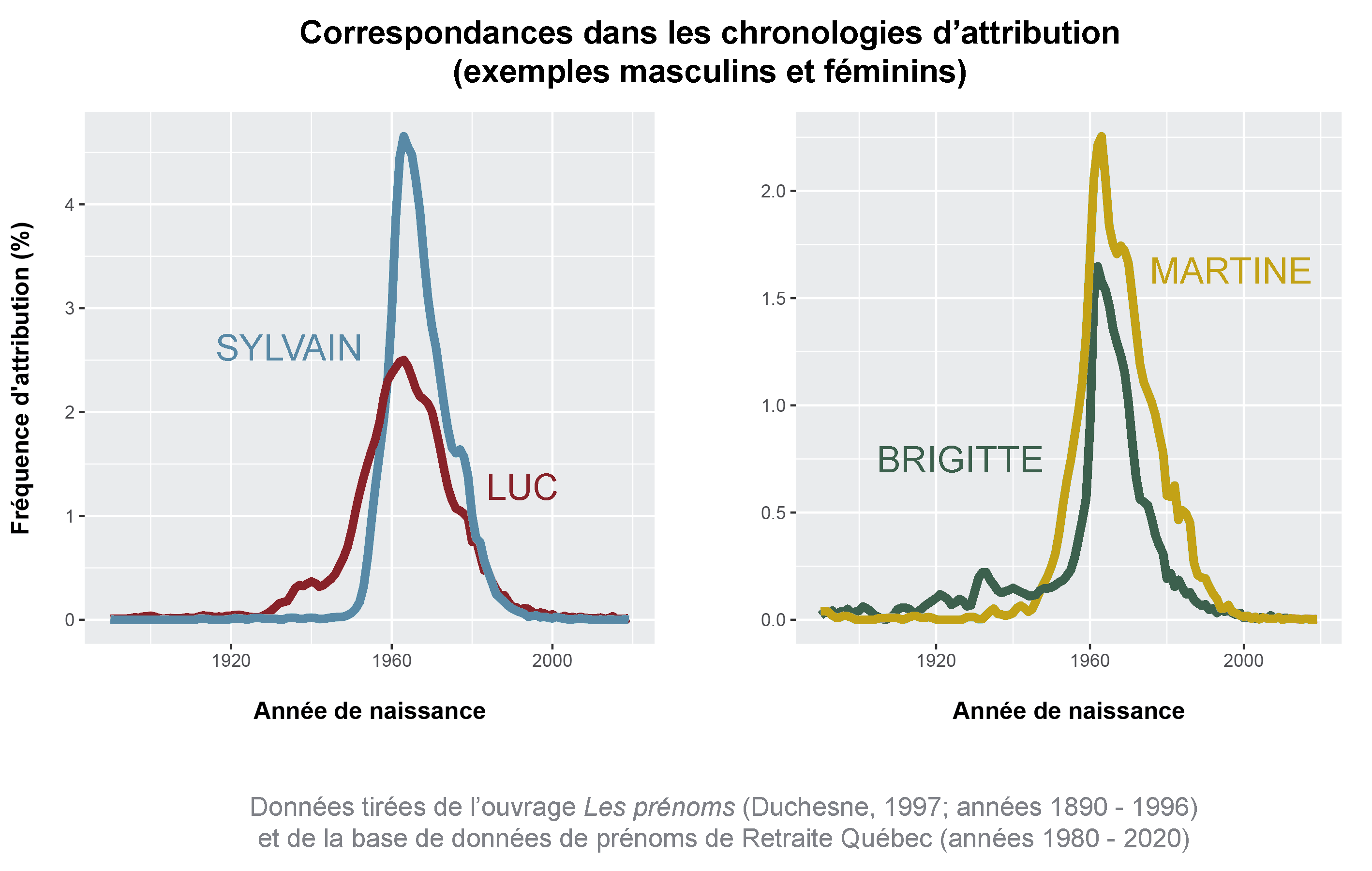
La même pratique peut être adoptée dans le traitement des corpus pour lesquels les témoins ne sont pas déjà identifiés par des pseudonymes déterminés. Il suffit de remplacer les noms apparaissant dans les entrevues par des équivalents, idéalement associés à la même génération (par exemple, Luc sera considéré un meilleur pseudonyme pour Sylvain que Donat ou Noah, Martine sera plus approprié pour Brigitte qu’Agnès ou Coralie). Pour ce faire, l’équipe du FDLQ a élaboré des outils systématisant la procédure. À partir des données présentées dans l’ouvrage Les prénoms, des plus rares au plus courants au Québec de Louis Duchesne (1997) et dans la base de données de Retraite Québec, nous avons créé deux documents. Le premier donne, pour chaque prénom, les 20 noms qui lui sont les plus semblables en ce qui a trait à la chronologie d’attribution (Luc et Sylvain sont jugés semblables puisqu’ils atteignent tous deux leur pic de popularité au milieu des années 1960, tout comme Martine et Brigitte). Le second document précise l’année où chaque prénom a atteint son pic de popularité. Cette liste peut être utile, lorsque le nom d’une personne n’est pas connu, pour attribuer un pseudonyme à partir de son âge (réel ou approximatif).
La protection de l’identité des locuteurs qui acceptent de participer à des projets de recherche est primordiale. Consciente de cette réalité, l’équipe du FDLQ a développé une méthode rigoureuse d’anonymisation, tout en essayant de maintenir le mieux possible l’intelligibilité des données publiées. À terme, nous espérons que la procédure de pseudonymisation permettra de rendre aux fichiers anonymisés le naturel, la spontanéité et la cohérence des originaux. Nous croyons également qu’elle pourrait faciliter les échanges portant sur des entrevues spécifiques, en particulier dans un contexte où les données du FDLQ sont appelées à former une base commune d’analyse et de discussion pour les chercheurs s’intéressant au français québécois.
Hugo Saint-Amant Lamy