Documents
Le Fonds de données linguistiques du Québec est composé (pour l'instant!) de plus de 33 000 documents![]() Unité de base d’un corpus (qui se définit comme une collection de documents), par exemple une œuvre littéraire, une chanson, une bande dessinée, un article de journal, une fiche dialectologique ou encore une entrevue. Dans le cadre du Fonds, une distinction est faite entre le contenu textuel du document (transcription) et le contenu binaire (version numérisée de l’original : image ou enregistrement audio)., répartis dans 24 corpus
Unité de base d’un corpus (qui se définit comme une collection de documents), par exemple une œuvre littéraire, une chanson, une bande dessinée, un article de journal, une fiche dialectologique ou encore une entrevue. Dans le cadre du Fonds, une distinction est faite entre le contenu textuel du document (transcription) et le contenu binaire (version numérisée de l’original : image ou enregistrement audio)., répartis dans 24 corpus![]() Ensemble de textes établi selon un principe de documentation exhaustive, un critère thématique ou exemplaire en vue de leur étude linguistique (définition tirée d'Usito)..
Ensemble de textes établi selon un principe de documentation exhaustive, un critère thématique ou exemplaire en vue de leur étude linguistique (définition tirée d'Usito)..
Sommaire
Documents du Fonds
La page Documents du Fonds montre la liste de tous les documents que le Fonds de données linguistiques du Québec a réunis à travers ses corpus, ainsi que quelques statistiques générales. Les principales caractéristiques de chaque document sont affichées dans les colonnes du tableau.

On accède à la page Documents du Fonds par la page d'accueil du FDLQ, en cliquant sur les liens ou le bouton vert au centre de la page. On peut aussi y accéder à partir de n'importe quelle page du FDLQ en cliquant sur l'onglet Documents qui se trouve tout juste en dessous du logo du Fonds.

Documents du corpus
L'onglet Documents du corpus affiche tous les documents qui constituent un corpus. Un lien permet d'accéder à chaque document individuellement : en cliquant sur ce lien, c'est la page individuelle de chaque document qui s'affiche. L'onglet Lexique du corpus permet de consulter le lexique spécifique du corpus.
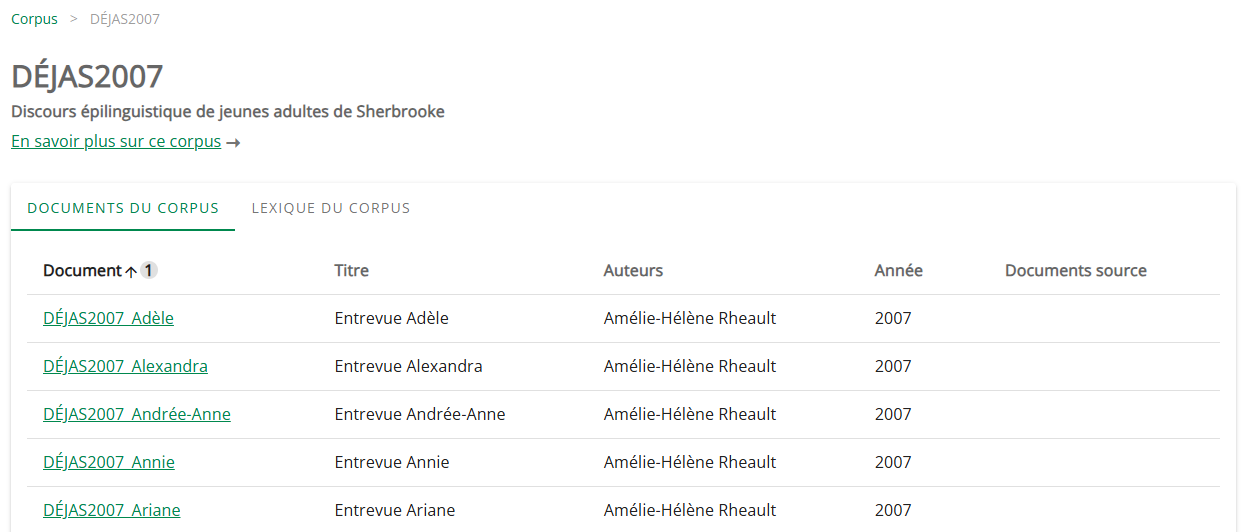
Document individuel
Cette page comprend une série d'onglets. Par défaut, c'est le lexique du document qui s'affiche. Le choix des autres onglets qu'on peut ouvrir varie selon la nature du document (texte intégral et document intégral pour les documents écrits, transcription avec audio pour les enregistrements sonores) et selon les autorisations obtenues pour diffuser certains contenus (il arrive par exemple que nous n'ayons pas le droit de diffuser une transcription complète). L'identifiant des documents est spécifique à chaque corpus.

Texte intégral
L'onglet Texte intégral affiche le texte intégral du document converti en caractères exploitables par un système informatique. Par exemple, ce texte intégral tiré du document Bégon-1748-001 du corpus Bégon.

Document original
L'onglet Document original affiche le document numérisé original. Par exemple, ce document original tiré du document Bégon-1748-001 du corpus Bégon.

Transcription avec audio
L'onglet Transcription avec audio permet de consulter la transcription du document, avec son fichier audio. Par exemple, cette transcription avec audio tirée du document PFC-Québec_Grande-Rivière_cqhdb1l du corpus PFC-Québec.
Lorsqu'on fait jouer l'enregistrement, la transcription est automatiquement synchronisée et un surlignage gris indique ce qui est prononcé. Cliquez n'importe où dans la transcription pour jouer l'extrait en question.
![]()
Au besoin, consultez le document d'aide consacré au lecteur audio.
Passage
L'onglet Passage ne s'affiche que si on clique sur l'icône représentant trois points de suspension à partir de la concordance![]() Liste des résultats d’une requête textuelle où les éléments recherchés sont affichés dans leur contexte., après avoir effectué une recherche. L'onglet Passage affiche 50 mots
Liste des résultats d’une requête textuelle où les éléments recherchés sont affichés dans leur contexte., après avoir effectué une recherche. L'onglet Passage affiche 50 mots![]() Dans le contexte de la plateforme FDLQ, mot n’est pas utilisé dans le sens d’« unité lexicale » qu’il prend en linguistique, mais plutôt comme synonyme de mot-forme (mot séparé par des espaces) ou encore de token. Les mots faisant partie du lexique d’un document ou d’un corpus correspondent ainsi à l’ensemble des tokens qu’on y trouve; suivant cette logique, pomme de terre correspond à trois tokens. avant le mot pivot
Dans le contexte de la plateforme FDLQ, mot n’est pas utilisé dans le sens d’« unité lexicale » qu’il prend en linguistique, mais plutôt comme synonyme de mot-forme (mot séparé par des espaces) ou encore de token. Les mots faisant partie du lexique d’un document ou d’un corpus correspondent ainsi à l’ensemble des tokens qu’on y trouve; suivant cette logique, pomme de terre correspond à trois tokens. avant le mot pivot![]() Dans une concordance, le mot (ou la suite de mots) choisi pour la recherche, accompagné de son contexte et mis en évidence typographiquement. L’acronyme KWIC signifie KeyWord In Context, littéralement « mot-clé dans son contexte ». et 50 mots après (sauf pour le corpus BDTS, limité à 10 mots avant et après).
Dans une concordance, le mot (ou la suite de mots) choisi pour la recherche, accompagné de son contexte et mis en évidence typographiquement. L’acronyme KWIC signifie KeyWord In Context, littéralement « mot-clé dans son contexte ». et 50 mots après (sauf pour le corpus BDTS, limité à 10 mots avant et après).

Voir aussi
Dernière modification : 26 mai, 2025